没有接触过编程的同学,可能对编码没有太多的概念,从而会在编程中碰到一些自己无法理解的问题
这里给大家普及一下编码的概念
计算机是怎么存储信息的?
计算机其实只会做加减法,我们看到的视频,听到的音乐,其实都是加减法运算后的结果,乘法,除法都可以通过加减法实现,加减法运算只能对数字进行运算。在我们生活中,通常都使用十进制,也有十二进制(生效,12小时制),七进制(周),等等。所以十进制并不是唯一的,可以根据需要选择进制。
计算机是由各种芯片组成的系统,使用电来驱动,通过有电没电来记住状态,因此它只有两个状态,表示为1与0,要使用这两种状态来表示数字的话,就是二进制了,二进制逢二进一
二进制与十进制对比:
二进制 十进制 0 0 1 1 10 2 11 3 100 4 101 5 110 6 111 7 1000 8 1001 9
那么如何表示字符?
现在假设有这么一个对照表
| 编号 | 含义 |
| 1 | 我 |
| 2 | 你 |
| 3 | 他 |
| 4 | 爱 |
| 5 | 恨 |
| 6 | 打 |
| 7 | ? |
| 8 | . |
| 9 | ! |
在这个表中,每个字都对应一个编号,那么我们可以通过编号来表达意思
1437 - 查编号就可以知道这一句的意思是:我爱他?
2519 - 查编号就可以知道这一句的意思是:你恨我!
这种将字符编成一组数字的过程就是编码,如果把编码顺序改变,那表达的意思也不一样,所以计算机的编码有一些统一的编码规范
ASCII码
ascii码可以说计算机的编码基础了,它规定了英文字符,数字字符,以及一些其他符号的编码,由IBM公司完成最后的编制工作,编制编码的时候,计算机还比较原始,内存是8位的,因此也只能用八位二进制来表示:0000 0000 ~ 1111 1111 (0~127),因此能表示128个字符
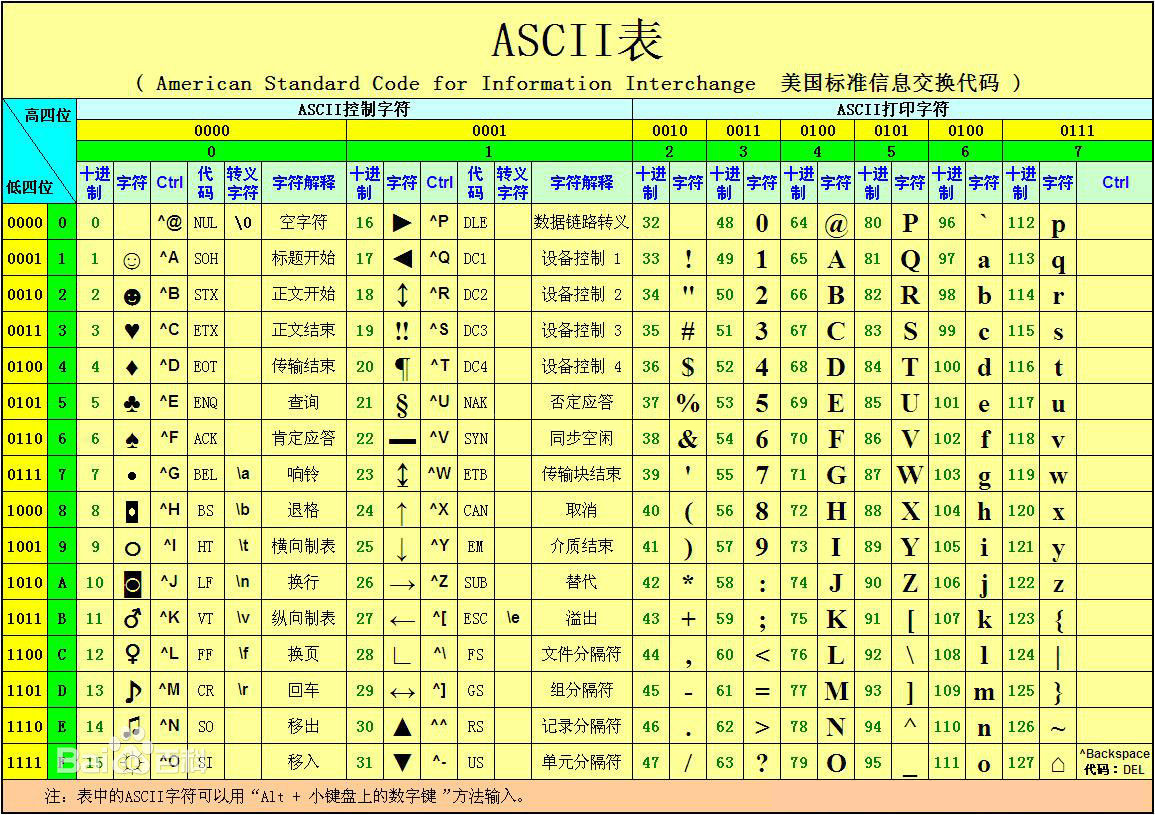
图中的高4位是指 XXXX 0000中的XXXX部分,低四位是指 0000 XXXX中的XXXX部分
0000 0000 ~ 0000 1111 高4位为0 低4位从0~15
0001 0000 ~ 0001 1111 高4位为1 低4位从0~15
依此类推。
Python提供的ASCII码相关的函数
可以在python中查看某个字符的ascii编码,或者根据数字查看这个数字代表的ascii字符
# 查看字符a的编码
ord("a")
# 查看大写字符A的编码
ord("A")
# 根据编码数字获得字符字面值
chr(97)
chr(122)
汉字编码
汉字就不是128个字符能解决的事情了,常用的就有3000个,所以八位二进制根本解决不了,那么可以通过多个八位组成,作为传承,每八位作为一个字节,如果16位就称为二个字节长,如果是24位就称为三个字节长
汉字常用的编码有GB2312, GBK, UTF8编码
汉字编码规则是两个字节,也就是16位,能表达65536个字符,这种通过两个字节编码的方案称为 ANSI 编码,又称为"MBCS(Muilti-Bytes Charecter Set,多字节字符集)"
其他韩文,日文都有自己的类似的编码,中文的编码名称为GB2312,由6763个常用汉字和682个全角的非汉字字符组成。其中汉字根据使用的频率分为两级。一级汉字3755个,二级汉字3008个。
中文的另一个编码方案是GBK,K就是扩展的意思,用于解决人名、古汉语等方面出现的罕用字。
在繁体中文区域,使用Big5编码,在以前玩台湾的游戏,会出现乱码现象,就是因为Big5与GB2312不是同一套编码原因。
编码的全球化
随着全球化进程,各国的文字都需要编码,如果继续维护各自的编码就容易出现乱码现象,比如说gb2312的网页,如果在台湾地区使用big5打开,就是乱码,不能正常显示,需要选择正确的编码,这样就容易出错,比较繁琐。
在这种情况下,出现了unicode编码
Unicode编码
Unicode使用四个字节表示一个字符,涵盖了全世界的文字字符,当用unicode编码表达ascii码时,就会空闲很多位,这就造成内存的浪费,所以效率不高,所以又发展出了UTF-8编码
UTF-8编码
utf-8编码或者utf8编码是Unicode编码的一种可变长度实施方案
在utf-8中,字符不同,长度也不同
ascii字符 使用一个字节长度
欧洲字符 使用二个字节长度
中文字符 使用三个字节长度
从而提高了内存使用效率
python3环境下默认就是utf-8编码
UTF-8中的8表示最少8位,另外还有utf-16,utf-32表示最少16位,最少32位
BASE64编码
另外还有一种编码为BASE64编码,用于网络中传输数据,这在课程的api接口中有专门的介绍

讨论区